
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Paper • 2509.22186 • Published • 159
![]()

![]()
![]()
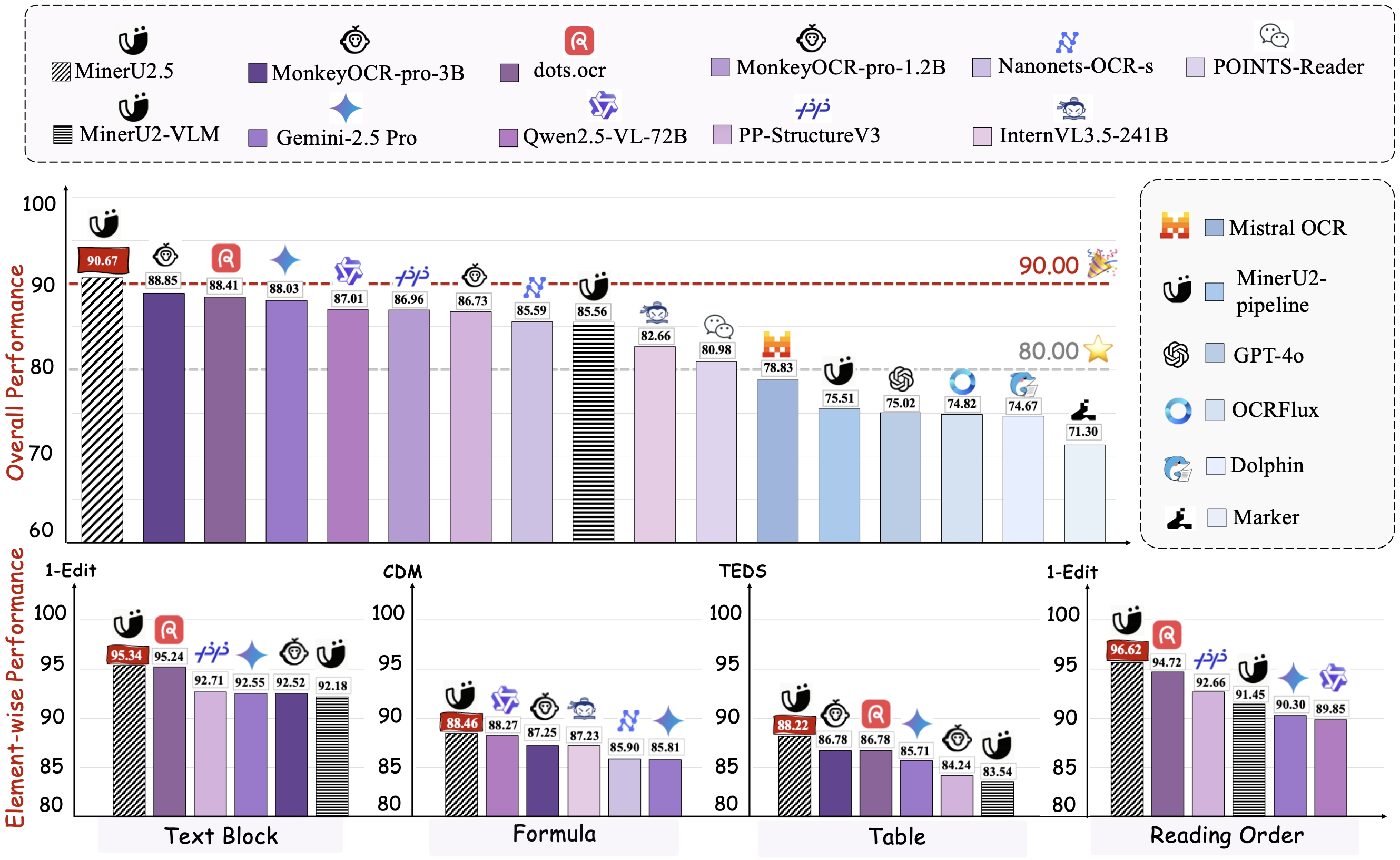
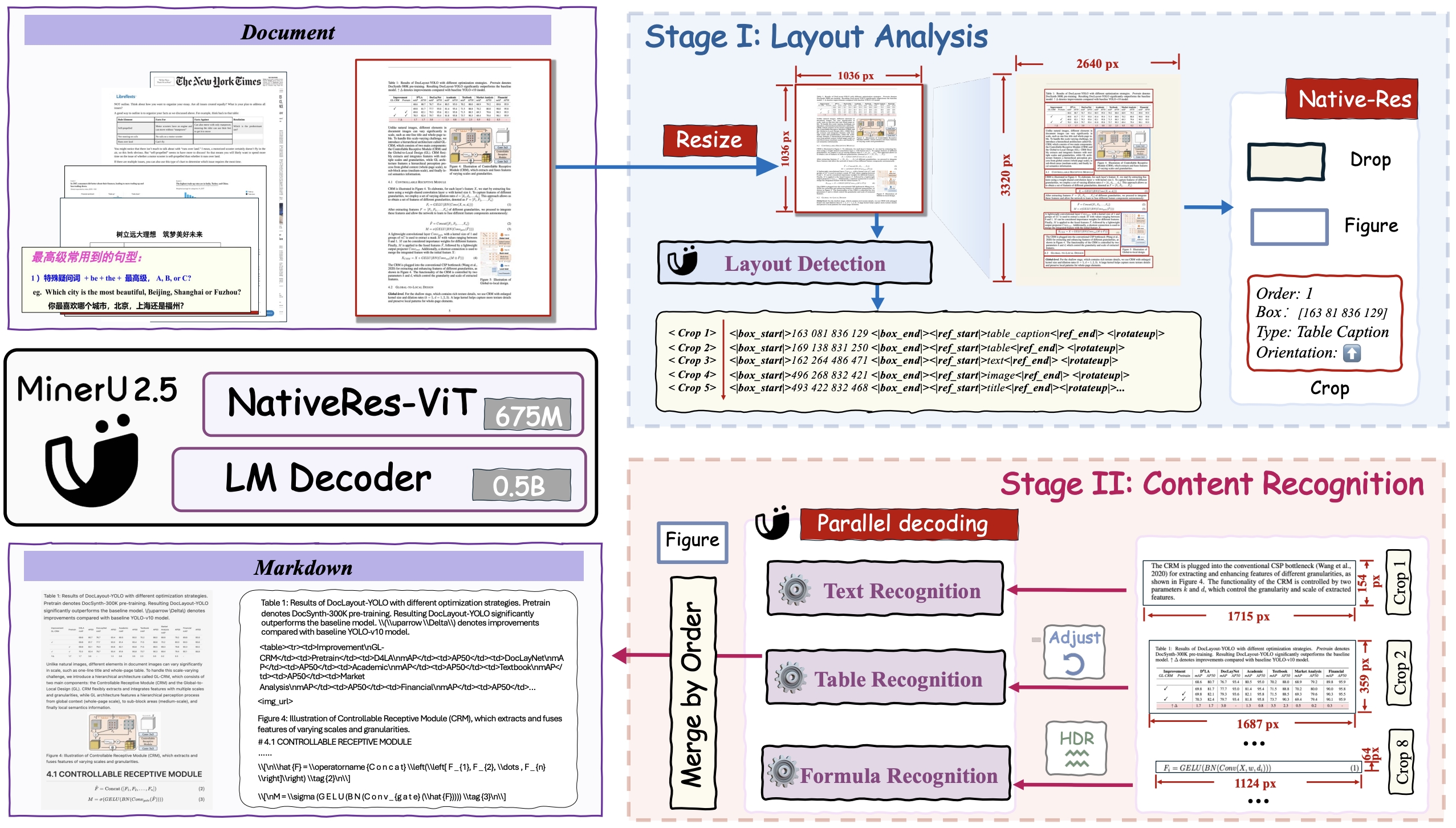
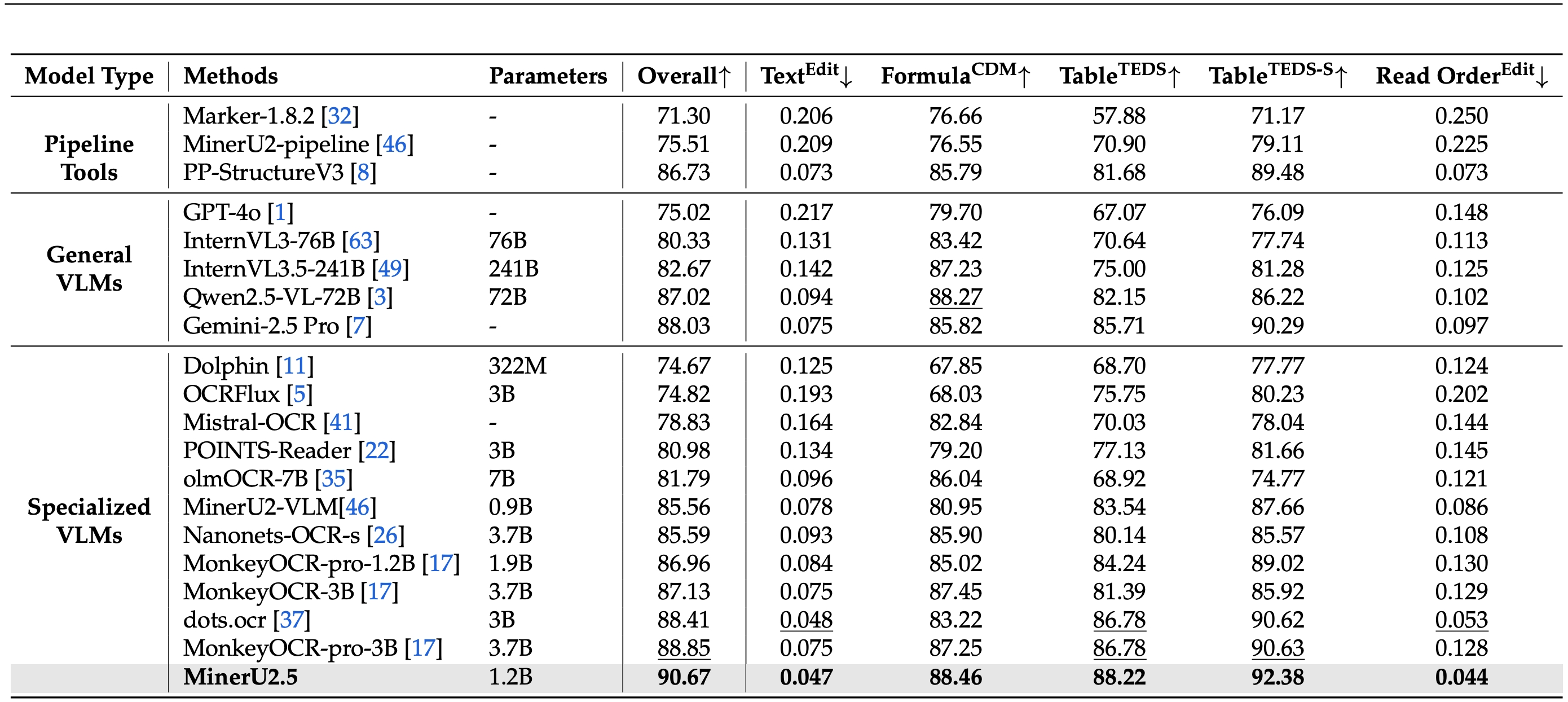
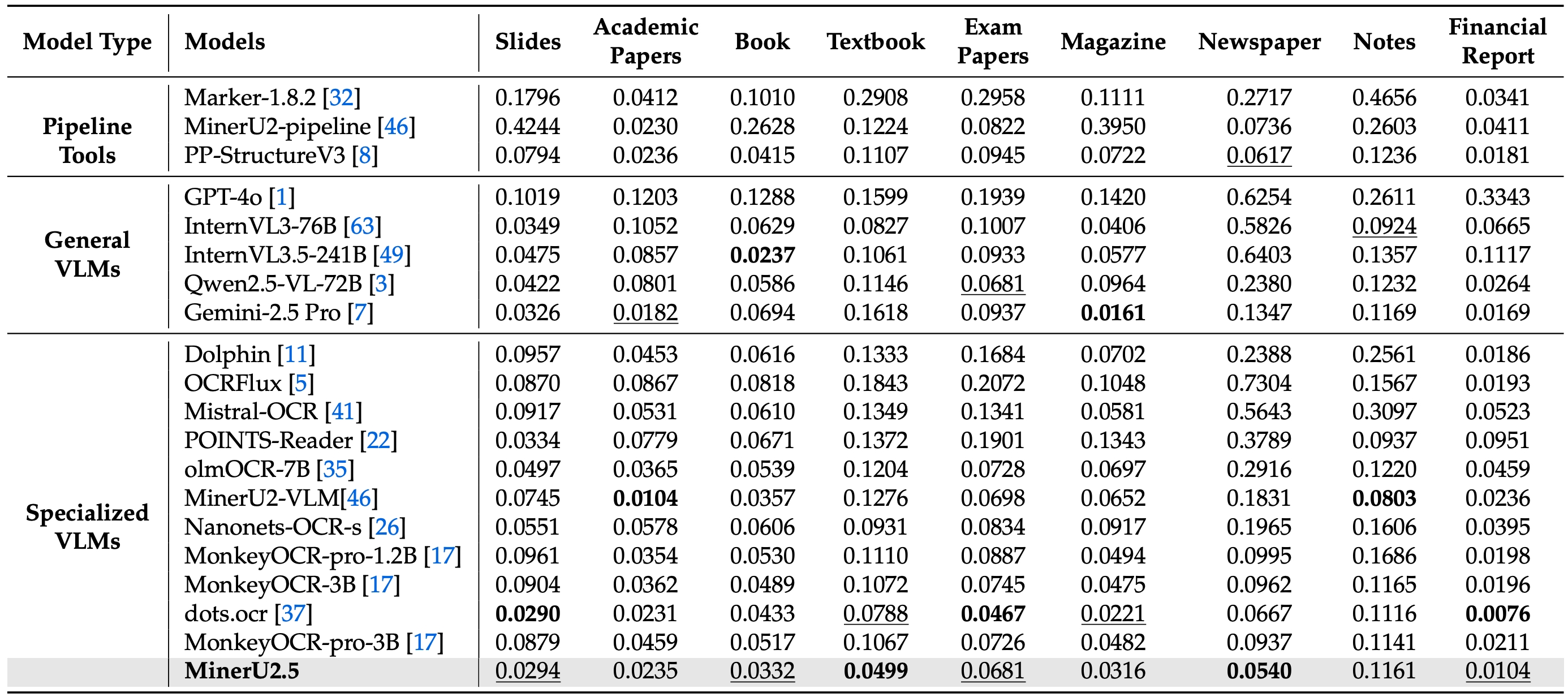
MinerU2.5 is a 1.2B-parameter vision-language model for document parsing that achieves state-of-the-art accuracy with high computational efficiency. It adopts a two-stage parsing strategy: first conducting efficient global layout analysis on downsampled images, then performing fine-grained content recognition on native-resolution crops for text, formulas, and tables. Supported by a large-scale, diverse data engine for pretraining and fine-tuning, MinerU2.5 consistently outperforms both general-purpose and domain-specific models across multiple benchmarks while maintaining low computational overhead.
For convenience, we provide mineru-vl-utils, a Python package that simplifies the process of sending requests and handling responses from MinerU2.5 Vision-Language Model. Here we give some examples to use MinerU2.5. For more information and usages, please refer to mineru-vl-utils.
📌 We strongly recommend using vllm for inference, as the vllm-async-engine can achieve a concurrent inference speed of 2.12 fps on one A100.
# For `transformers` backend
pip install "mineru-vl-utils[transformers]"
# For `vllm-engine` and `vllm-async-engine` backend
pip install "mineru-vl-utils[vllm]"
This model is used in production via the MinerU Open API — no GPU required. Two deployment tracks:
| Track | Requirement | Best for |
|---|---|---|
| 🖥️ Self-hosted | GPU (A100 recommended) | Research, private deployment |
| ☁️ Cloud API | API token (free tier available) | Production use, no GPU needed |
Use mineru-vl-utils to run MinerU2.5 locally on your own GPU.
pip install "mineru-vl-utils[transformers]"
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from PIL import Image
from mineru_vl_utils import MinerUClient
model = Qwen2VLForConditionalGeneration.from_pretrained(
"opendatalab/MinerU2.5-2509-1.2B", dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(
"opendatalab/MinerU2.5-2509-1.2B", use_fast=True
)
client = MinerUClient(backend="transformers", model=model, processor=processor)
print(client.two_step_extract(Image.open("/path/to/page.png")))
# pip install "mineru-vl-utils[vllm]"
from vllm import LLM
from PIL import Image
from mineru_vl_utils import MinerUClient, MinerULogitsProcessor
client = MinerUClient(
backend="vllm-engine",
vllm_llm=LLM(model="opendatalab/MinerU2.5-2509-1.2B",
logits_processors=[MinerULogitsProcessor])
)
print(client.two_step_extract(Image.open("/path/to/page.png")))
# pip install "mineru-vl-utils[vllm]"
import asyncio, io, aiofiles
from vllm.v1.engine.async_llm import AsyncLLM
from vllm.engine.arg_utils import AsyncEngineArgs
from PIL import Image
from mineru_vl_utils import MinerUClient, MinerULogitsProcessor
async_llm = AsyncLLM.from_engine_args(
AsyncEngineArgs(model="opendatalab/MinerU2.5-2509-1.2B",
logits_processors=[MinerULogitsProcessor])
)
client = MinerUClient(backend="vllm-async-engine", vllm_async_llm=async_llm)
async def main():
async with aiofiles.open("/path/to/page.png", "rb") as f:
image = Image.open(io.BytesIO(await f.read()))
print(await client.aio_two_step_extract(image))
asyncio.run(main())
async_llm.shutdown()
Free Flash mode available without a token (20 pages / 10 MB per file).
# Windows (PowerShell)
irm https://cdn-mineru.openxlab.org.cn/open-api-cli/install.ps1 | iex
# macOS / Linux
curl -fsSL https://cdn-mineru.openxlab.org.cn/open-api-cli/install.sh | sh
# Flash extract — no login, Markdown only
mineru-open-api flash-extract report.pdf
# Precision extract — token required
mineru-open-api auth
mineru-open-api extract report.pdf -o ./output/
# pip install mineru-open-sdk
from mineru import MinerU
# Flash mode — free, no token
result = MinerU().flash_extract("report.pdf")
print(result.markdown)
# Precision mode — tables, formulas, large files
client = MinerU("your-token") # https://mineru.net/apiManage/token
result = client.extract("report.pdf")
print(result.markdown)
# pip install langchain-mineru
from langchain_mineru import MinerULoader
# Flash mode — free, no token
docs = MinerULoader(source="report.pdf").load()
print(docs[0].page_content)
# Precision mode — full RAG pipeline
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
docs = MinerULoader(source="manual.pdf", mode="precision", token="your-token",
formula=True, table=True).load()
chunks = RecursiveCharacterTextSplitter(chunk_size=1200, chunk_overlap=200).split_documents(docs)
vectorstore = FAISS.from_documents(chunks, OpenAIEmbeddings())
results = vectorstore.similarity_search("key requirements", k=3)
llama-index-readers-mineru is an official LlamaIndex Reader.
# pip install llama-index-readers-mineru
from llama_index.readers.mineru import MinerUReader
# Flash mode — free, no token
docs = MinerUReader().load_data("report.pdf")
print(docs[0].text)
# Precision mode — OCR, formula, table
docs = MinerUReader(mode="precision", token="your-token",
ocr=True, formula=True, table=True).load_data("paper.pdf")
# Full RAG pipeline
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(docs)
response = index.as_query_engine().query("Summarize the key findings")
print(response)
mineru-open-mcp lets any MCP-compatible AI client parse documents as a native tool. No token required in Flash mode.
{
"mcpServers": {
"mineru": {
"command": "uvx",
"args": ["mineru-open-mcp"],
"env": { "MINERU_API_TOKEN": "your-token" }
}
}
}



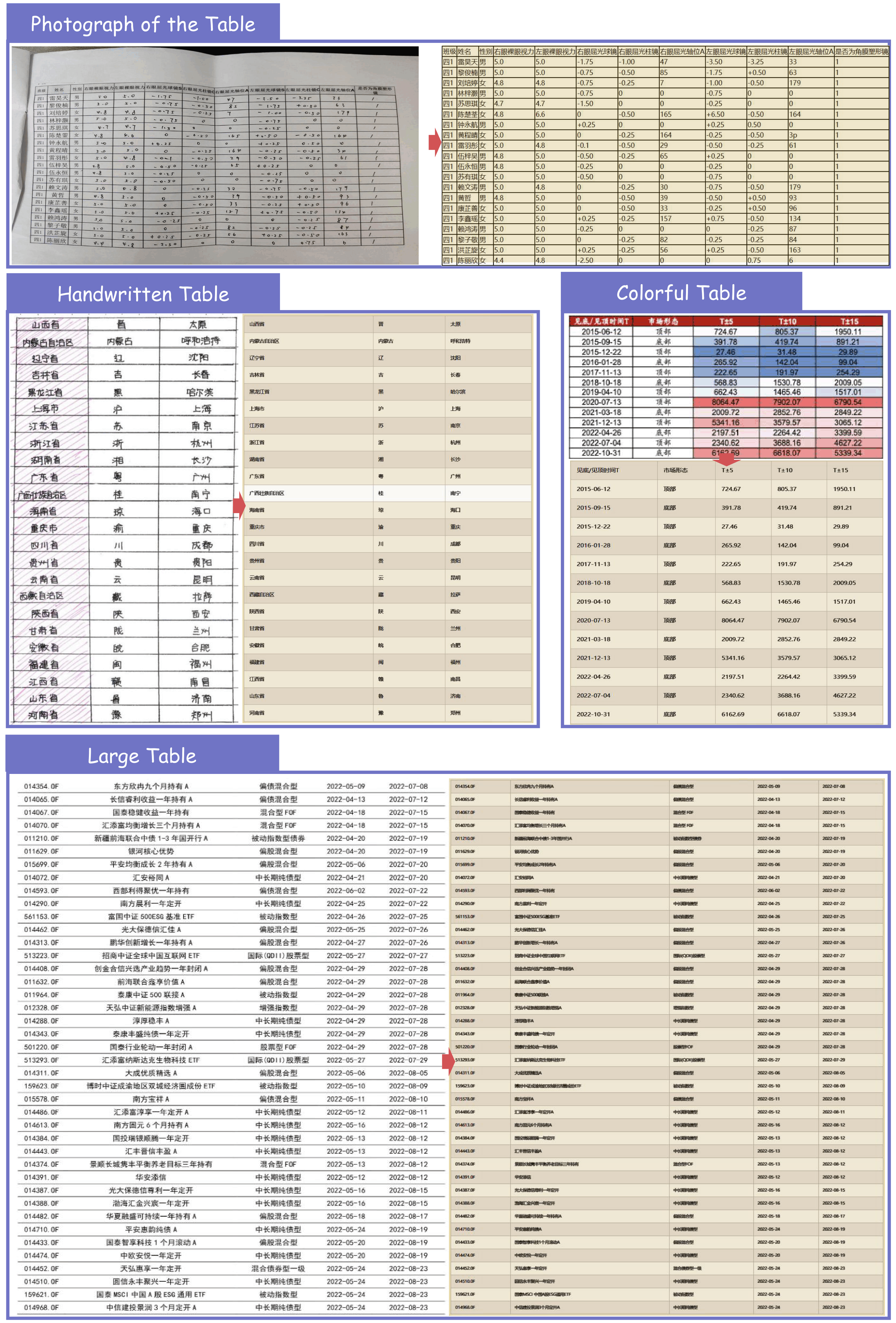
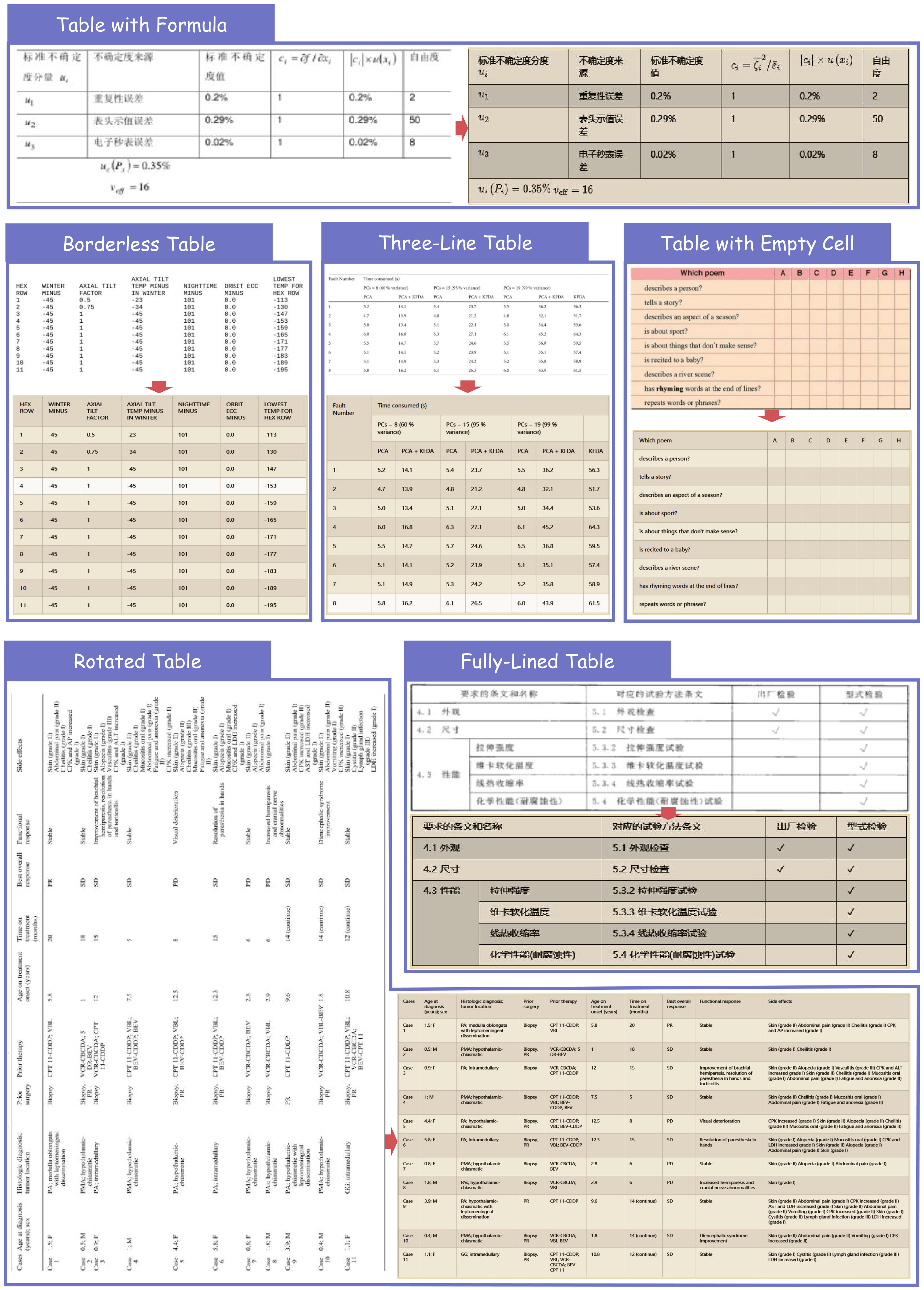
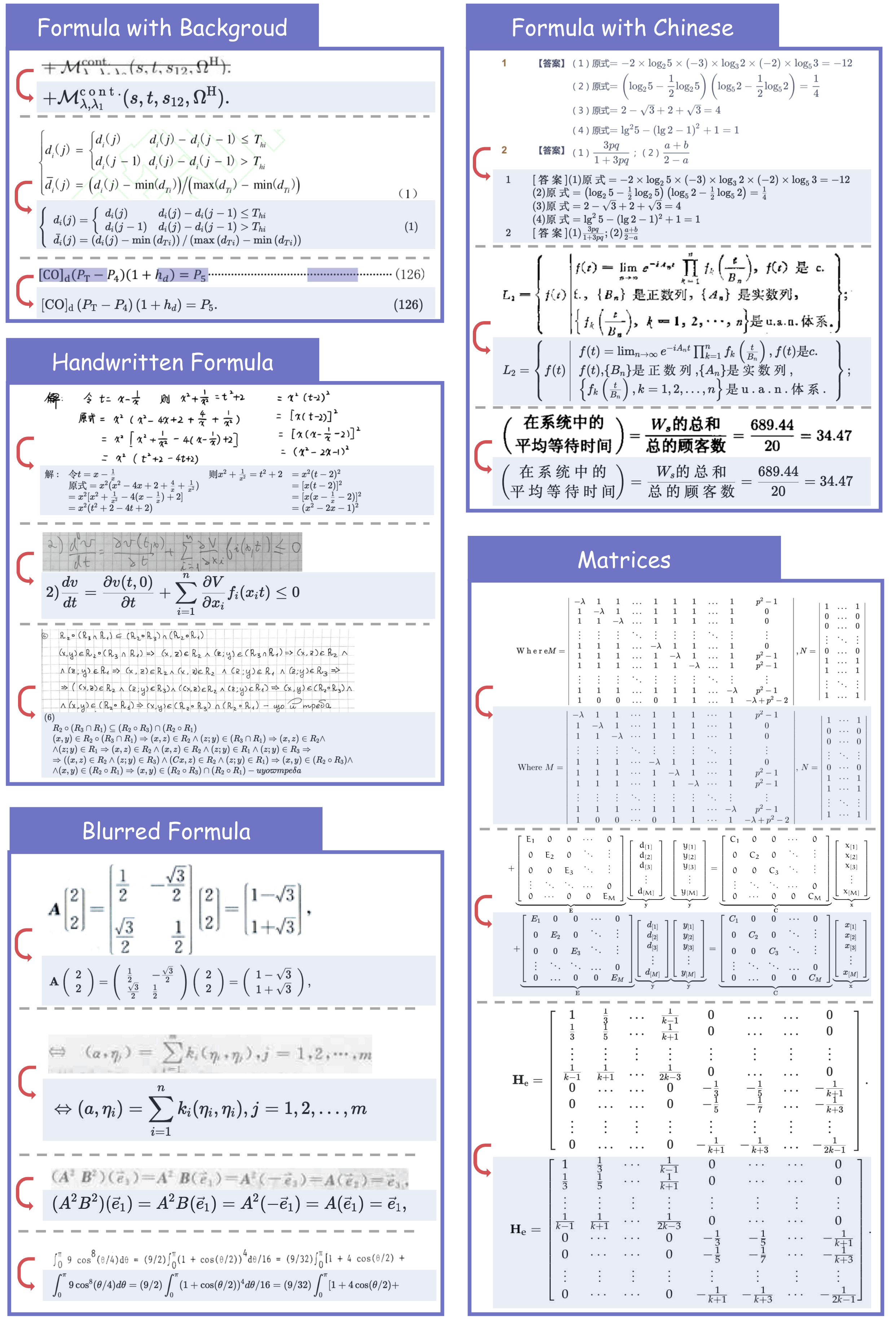

We would like to thank Qwen Team, vLLM, OmniDocBench, UniMERNet, PaddleOCR, DocLayout-YOLO for providing valuable code and models. We also appreciate everyone's contribution to this open-source project!
If you find our work useful in your research, please consider giving a star ⭐ and citation 📝 :
@misc{niu2025mineru25decoupledvisionlanguagemodel,
title={MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing},
author={Junbo Niu and Zheng Liu and Zhuangcheng Gu and Bin Wang and Linke Ouyang and Zhiyuan Zhao and Tao Chu and Tianyao He and Fan Wu and Qintong Zhang and Zhenjiang Jin and others},
year={2025},
eprint={2509.22186},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.22186},
}
